


server
command. This will save the considerable startup time for new Java
processes, and allow the Java virtual machine to just-in-time compile
the bytecode for further efficiency.$ java -server -jar Utool.jar ...Because of the increased time for startup and compilation, this works best if you also run Utool in server mode and send it commands via a socket. If you do, you can encourage the JVM to JIT-compile the solver by passing the
--warmup option to the server.OutOfMemoryError and terminate the process. For most USRs that
you will encounter in practice (including almost all USRs in the HPSG
treebanks), the default limit of 256 MB will be sufficient. However,
for those cases where more memory is needed (e.g.
rondane-650.mrs.pl in the examples directory, which has about
2 ⋅ 1012 solved forms), you can allow Java to use more heap
space by calling it with the -Xmx512m option.LANG (see also man locale). If this is not possible on your system, you can also change Java's character encoding directly by setting the file.encoding property.$ LANG=de_DE.ISO8859-1 utool display some-usrAlternatively, you could pass the character encoding directly to Java as follows:
$ java -Dfile.encoding=ISO-8859-1 -jar Utool.jar ...Note that character encodings are only an issue if you want to display underspecified representations. If you want to solve an USR, or convert it into other formalisms, then Utool produces outputs based on the same encoding as the input.
"
etc., and performing the inverse replacement when decoding the
server's responses.
.
domcon-oz format from standard
input or a file and send it to the server as the argument of a
solve command. It will then wait for an answer from the server
(i.e., a list of solved forms in term-oz format) and print it
to standard out.
use IO::Socket;
# read a dominance constraint
$message = join('', <>);
# open connection
$socket = IO::Socket::INET->new("localhost:2802") or die $!;
# and send it to the server
print $socket <<EOF;
<utool cmd='solve' output-codec='term-oz'>
<usr codec='domcon-oz' string='$message'/>
</utool>
EOF
# shutdown output side of the socket
$socket->shutdown(1);
# print the answer
while (<$socket>) { print }
The key point here is that the client shuts down the side of the
socket that is used to send data from the client to the server. This
tells the server that the input is now complete and it should start
processing it.lkb-utool.lisp into the Lisp console
of a running LKB system, the internal MRS solver is replaced by
Utool. Technically, this file defines a function that sends the MRS
(in mrs-prolog syntax) to a Utool Server running on the local
machine on port 2802. It will then receive the solved forms from the
server, in plugging-lkb syntax, and pass them back to LKB.
Alternatively, if you load the file
lkb-utool-menu.lisp
into the Lisp console, two new commands are added to the context menu
for parse trees (see Fig. 244Integration with the LKB Workbenchfigure.2). The command
“Scoped MRS (utool solve)” calls Utool to compute all scopings of
the MRS for this parse tree, in the same way as just described. On the
other hand, the “Display MRS” command will ask the Utool Server to
perform a display command for the given MRS. You can then solve
and further manipulate the USR from the GUI. As before, these commands
also make the assumption that a Utool Server is running on the local
machine, port 2802.localhost:2802, you can change the host and/or port by setting the variables utool::*utool-host* and utool::*utool-port* to the values you want in the Lisp console.extract-gold.lisp, which can be found in the directory
tools/lkb in the Utool jar file. Proceed as follows:
rondane directory contains a file result.gz, which contains the actual annotations and has to be unzipped first.
(load "extract-gold") (utool::extract-prolog "erg/gold/rondane/result" "target-directory")You need to replace
target-directory with the name of the
directory in which you want the individual MRSs stored. This will
create a number of files with the extension .mrs.pl, one for
each sentence in the treebank. These files are suitable for reading
with the mrs-prolog input codec.
utool::extract-xml rather than
utool::extract-prolog. The arguments of both calls are the
same.
:solve t to the
extract-prolog call, the MRS constraint solver is applied to
each MRS expression, and the number of fully scoped MRS expressions is
stored in a file log in the target directory. This can be
useful to compare the results of the MRS solver and Utool, but can
take quite a while.
extract functions will work with the treebanks that are
distributed together with the ERG under the erg/gold directory,
but they will not work directly with the Redwoods corpus
[[]Oepen etal.2002], which is distributed separately and uses a
different internal format. See e.g.
http://wiki.delph-in.net/moin/RedwoodsTop for more information
about the Redwoods corpus, and how MRS structures can be extracted.As our benchmark example, we chose the Jotenheimen corpus, which like the Rondane corpus (cf. Section ?? above) is distributed together with the English Resource Grammar. The corpus contains analyses for 5135 sentences together with corresponding semantic representations based upon MRS. We extracted the MRS structures as described in Section ?? above and translated them into dominance graphs. Of the 5135 MRS structures in the corpus, 441 could not be translated, so we base the evaluation on a dataset of 4694 dominance graphs.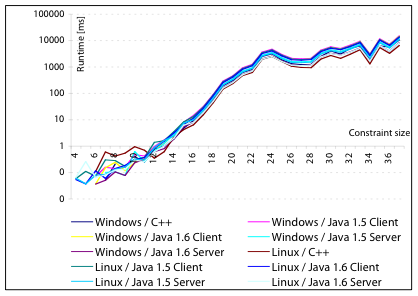
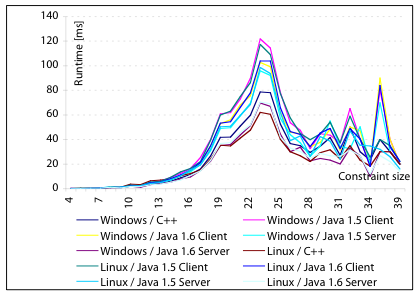
Figure 3: Runtimes for the commands solvable (left) and solve -n (right) of Utool 2.0.1 (C++) and 3.0 (Java) on Windows and Linux.
utool solvable (measuring how long it takes to compute the
chart and count all solved forms) and utool solve -n (measuring
how long it takes to compute the chart and then extract all solved
forms, without actually encoding or displaying them) on all dominance graphs with at most one million solved forms. We did this
using both Utool 2.0.1 (the last C++ version) and Utool 3.0 (the first
Java version) on all sentences. We ran Utool 3.0 in server mode (using
utool server) to eliminate the overhead for starting up the
JVM.-server JVM flag).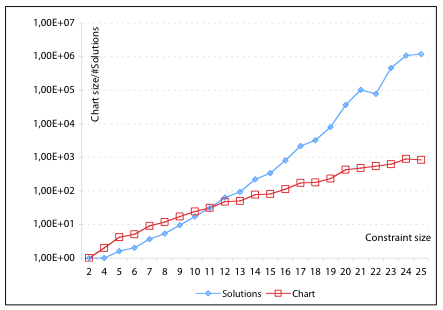
Figure 4: The size of the chart as compared to the number of solved forms described by the chart, for all dominance graphs in the Jotenheimen corpus with up to 25 fragments.